Meanwhile, you can join our community to learn about ML deployment from zero to scale.
We use cookies to improve user experience. Choose what cookies you allow us to use. You can read more about our Cookie Policy in our privacy policy


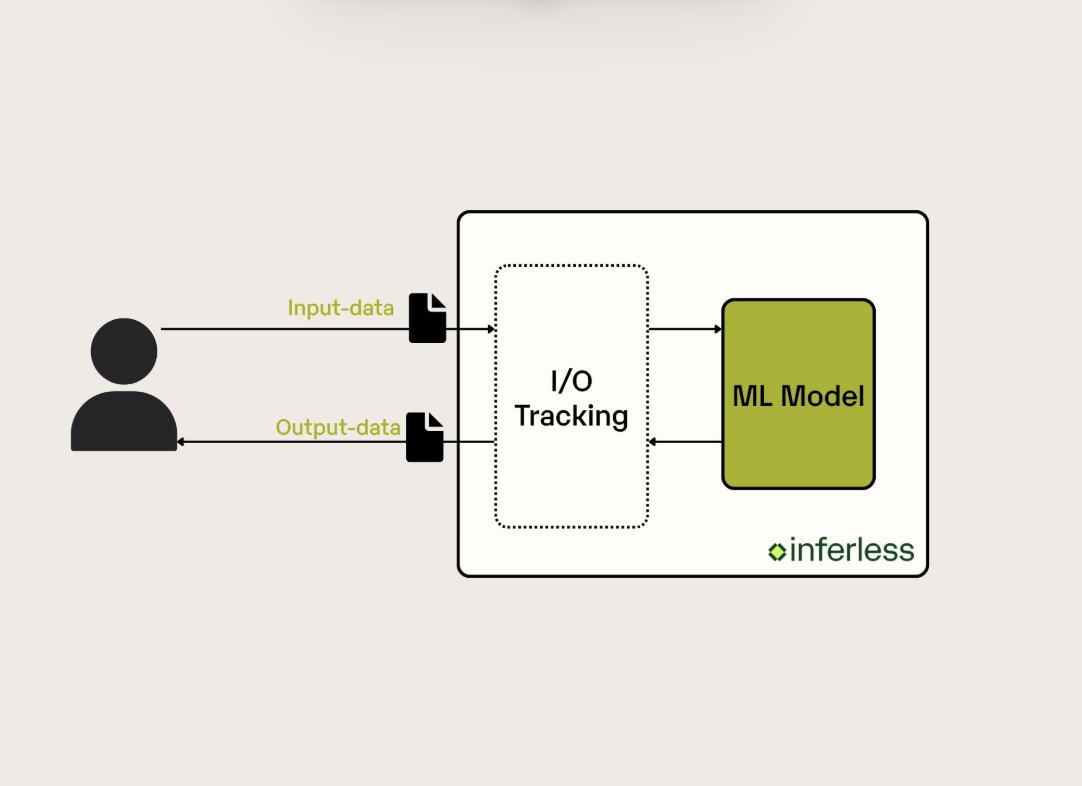




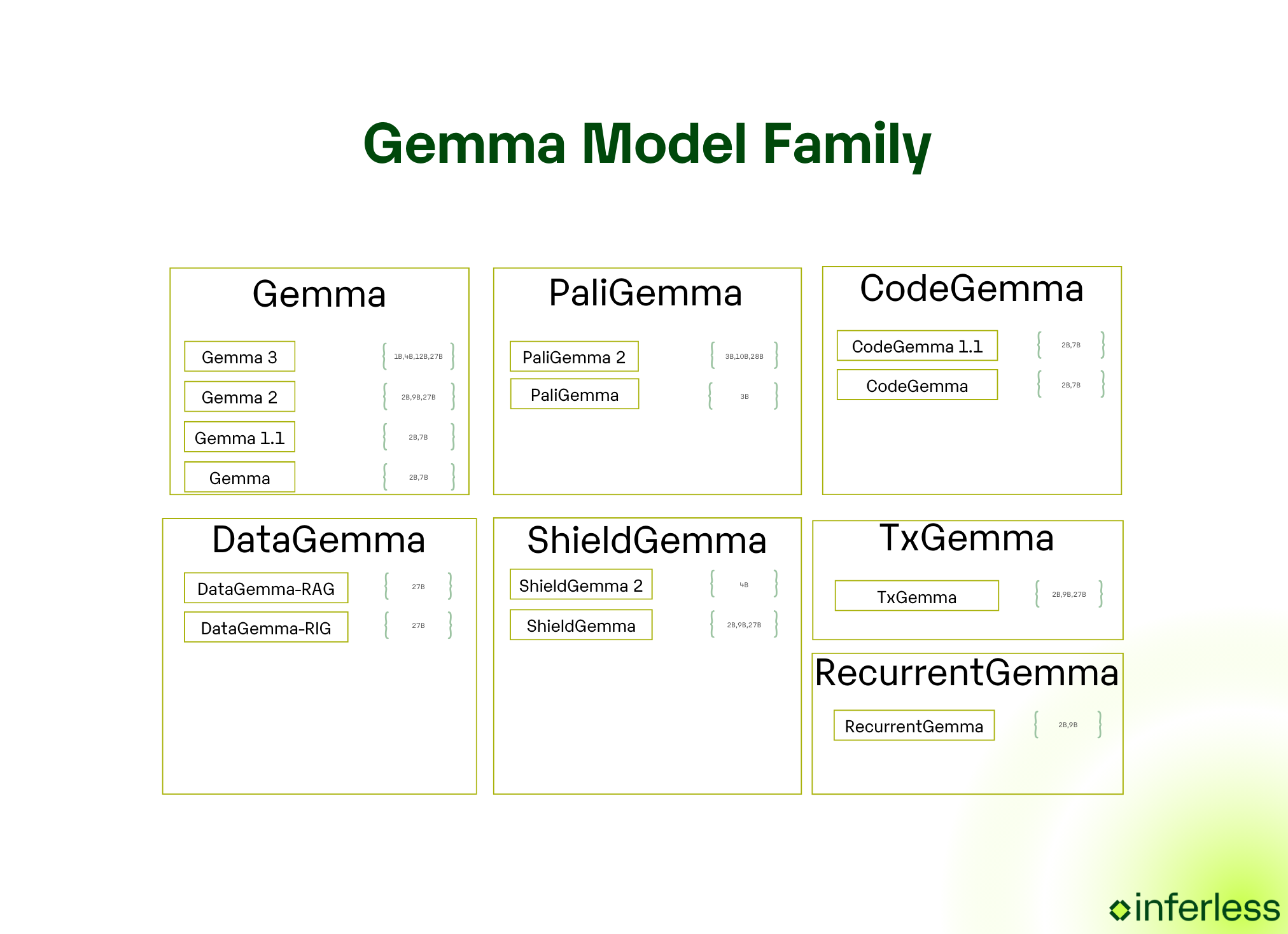
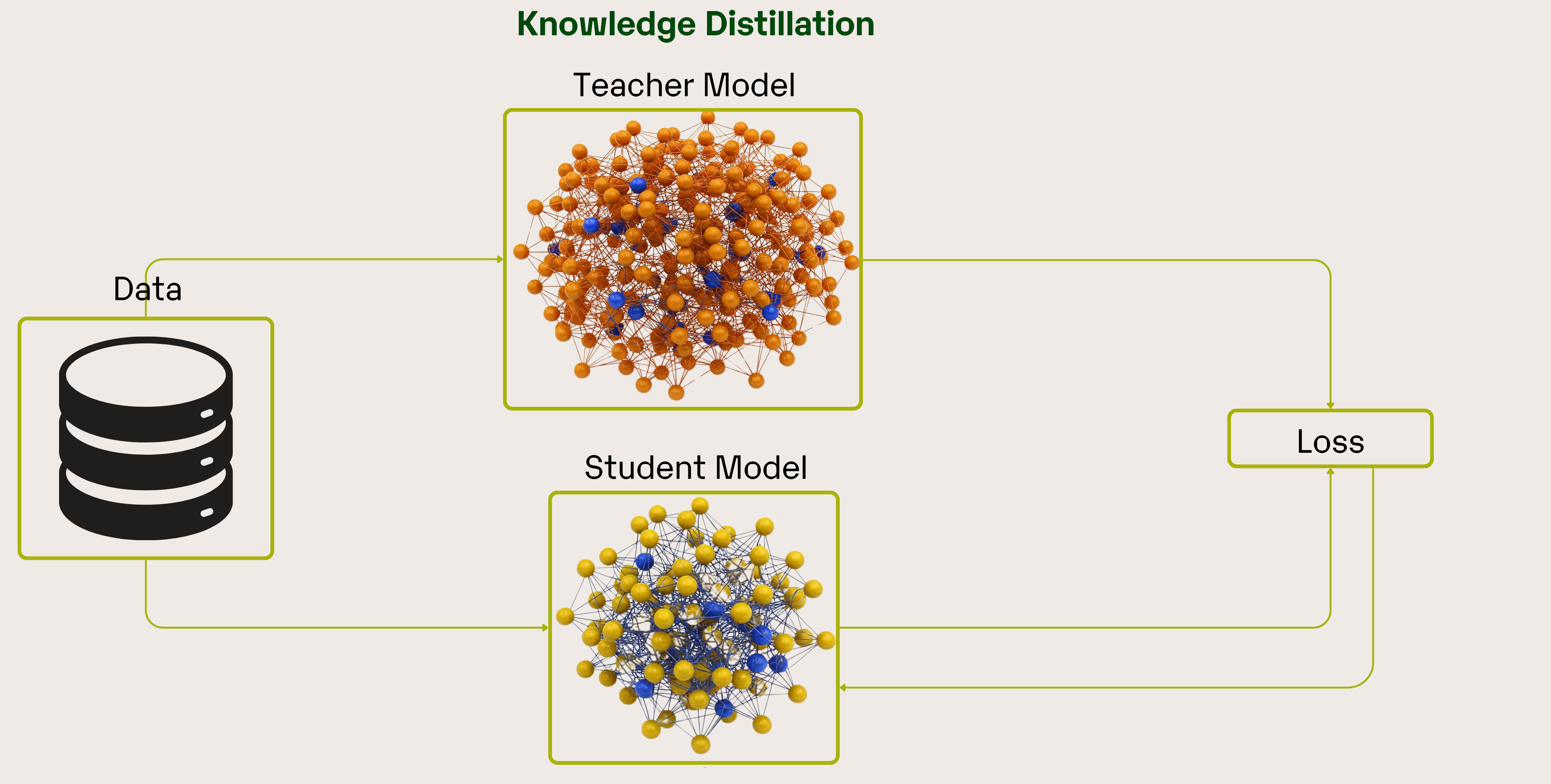
.png)












.png)



.png)
.png)
.png)
.png)

.png)





.svg)
