
A Beginner’s Guide to Code generation LLMs
.png)




I. Introduction
The release of GitHub Copilot in 2021 marked a watershed moment, demonstrating that AI could serve as a practical coding companion for millions of developers worldwide. Since then, the field has exploded with specialized models achieving remarkable performance across diverse programming tasks.
In today's rapidly evolving development landscape, coding LLMs address critical challenges including developer productivity bottlenecks, the growing complexity of modern software systems, and the increasing demand for faster time-to-market. These tools democratize programming by lowering the barrier to entry for newcomers while simultaneously amplifying the capabilities of experienced developers.
This analysis explores the intricate workings of coding LLMs, examines their diverse applications across the software development lifecycle, analyzes their current limitations and challenges, and peers into the future of AI-assisted programming.
II. How Coding LLMs Work
Coding LLMs are built upon the transformer architecture, the same foundational technology that powers models like GPT and BERT.
However, these models are specifically trained and fine-tuned on vast repositories of source code, making them exceptionally adept at understanding programming patterns, syntax, and semantics.

The transformer architecture excels at capturing long-range dependencies in sequential data, which is crucial for understanding code structure. When you write a function definition at the beginning of a file, the model can reference that context hundreds of lines later when generating a function call. This contextual awareness is fundamental to producing coherent, syntactically correct code.
Training Data Sources
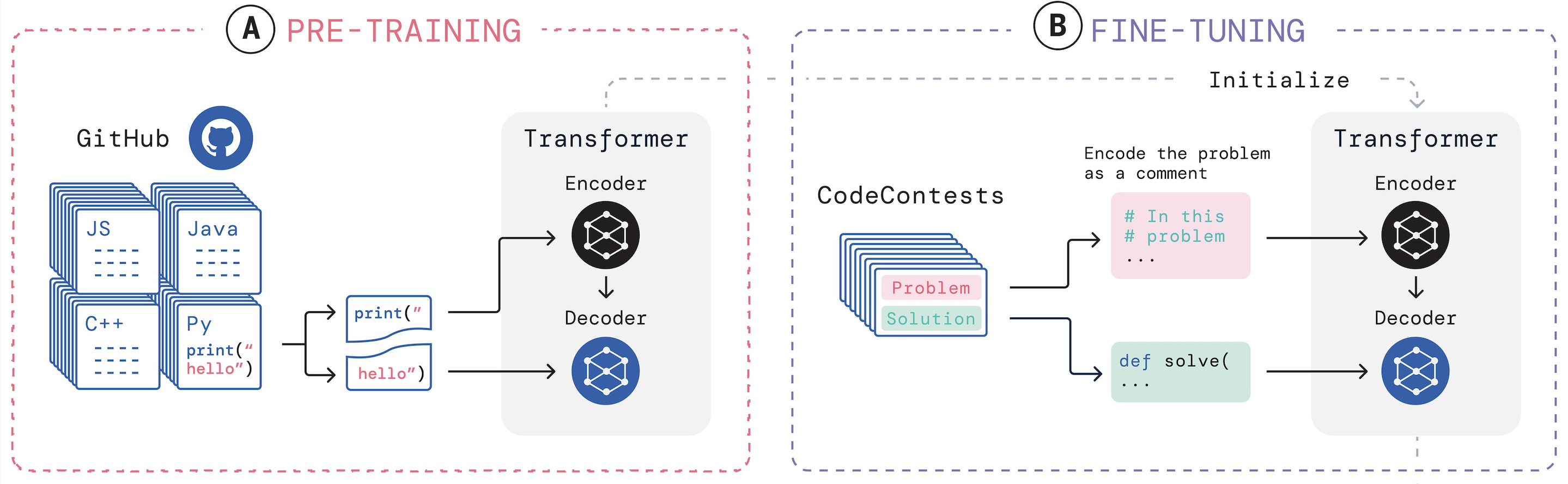
The latest coding LLMs are trained on massive, carefully curated datasets that combine multiple sources of code-related information, with each leading model taking distinct approaches to data collection, processing, and composition.
GitHub repositories form the backbone of virtually all coding LLMs, providing access to millions of open-source projects spanning hundreds of programming languages.
The diversity of GitHub's codebase ensures that models learn not just syntax and semantics, but also the contextual nuances of how different programming languages and frameworks are used in practice. This includes understanding project structure, dependency management, and the relationship between different files within a codebase.
Stack Overflow represents another crucial data source, contributing problem-solving patterns, debugging techniques, and detailed explanations of programming concepts. Unlike raw code repositories, Stack Overflow provides the Q&A format data that teaches models to associate natural language problem descriptions with their corresponding code solutions, making them more effective at translating human intent into functional code.
Other official documentation, API references, and technical guides serve as authoritative sources for language specifications, standard library usage, and framework conventions. This data ensures that models generate code that adheres to established standards and best practices rather than just mimicking patterns they've seen in repositories.
The Role of Instruction Tuning and Reinforcement Learning
Instruction tuning refines pre-trained models to better follow human instructions and preferences. This process involves training on carefully curated datasets of instruction-response pairs, teaching the model to understand various ways humans might request coding assistance.
Reinforcement Learning from Human Feedback (RLHF) further improves model performance by incorporating human preferences into the training process. Human evaluators rate model outputs on criteria like correctness, efficiency, and adherence to best practices, and these preferences are used to fine-tune the model's behavior.
This combination of techniques ensures that coding LLMs don't just generate syntactically correct code, but produce solutions that align with human expectations for quality, style, and appropriateness.
How to Measure "Best" Coding LLM
As developers and organizations increasingly rely on these models for tasks ranging from simple code completion to complex system refactoring, the ability to accurately measure their capabilities is paramount.
The Data-Contamination Problem
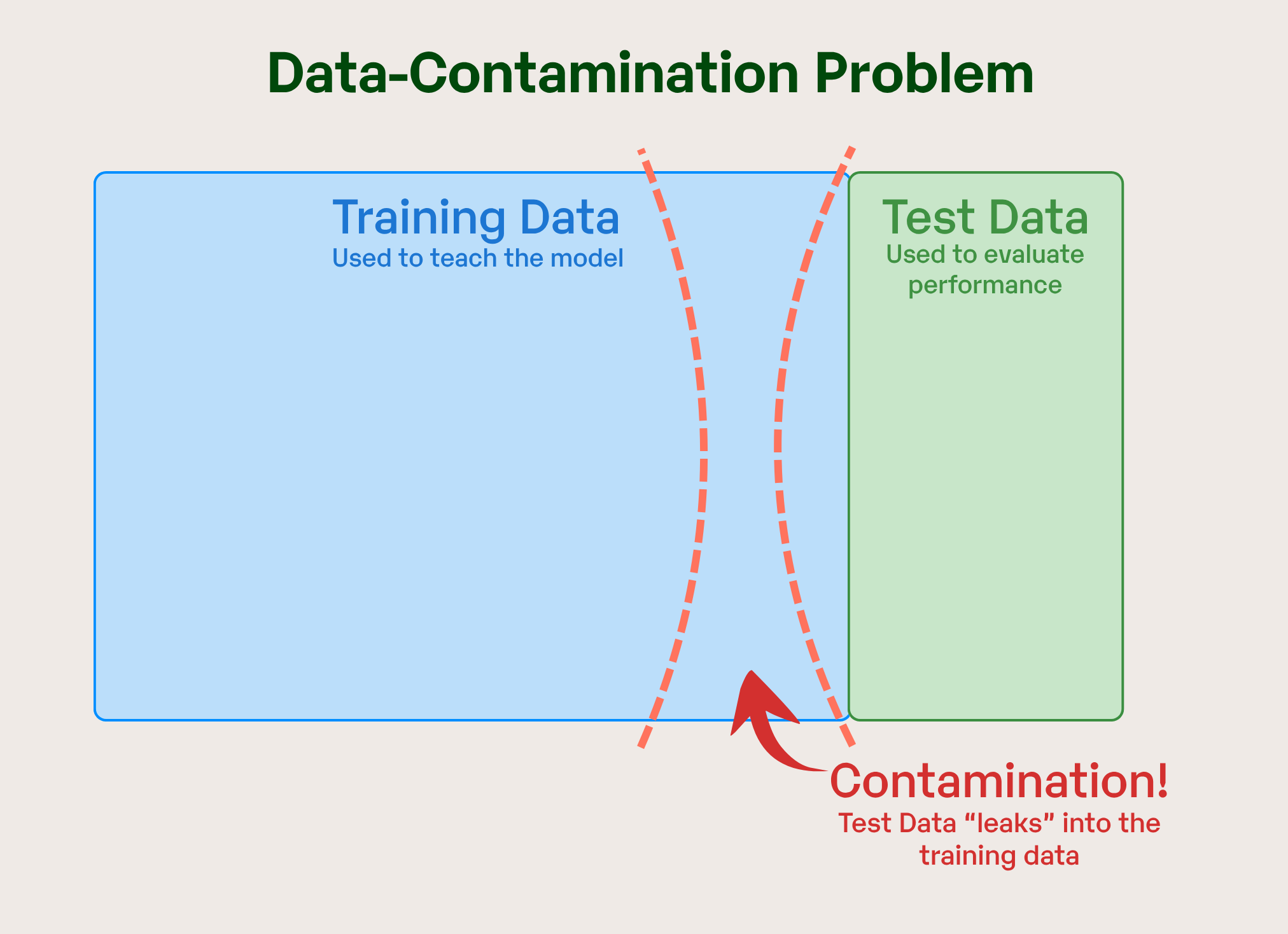
The most significant threat to reliable LLM evaluation is data contamination, where test set problems appear in training data. This phenomenon transforms capability assessment into memorization testing, leading to inflated performance metrics and distorted intelligence measures.
LiveCodeBench: A Dynamic and Holistic Approach to Evaluation
LiveCodeBench introduces a novel framework designed to be both holistic in its assessment and fundamentally resistant to data contamination.LiveCodeBench addresses contamination through continuous problem collection from ongoing contests on LeetCode, AtCoder, and CodeForces. Each problem includes original release date annotation, enabling "scrolling over time" evaluation that neutralizes contamination by testing models only on problems published after their training cutoff.
Why One Benchmark Isn’t Enough
While LiveCodeBench provides a robust, contamination-free, and holistic evaluation, no single benchmark can capture the full spectrum of coding-related tasks.
A comprehensive understanding of a model's capabilities requires a multi-faceted approach, incorporating benchmarks that test different skills and scenarios.
This section analyzes three key complementary benchmarks, SWE-bench Verified, HumanEval/MBPP, and RepoBench, each providing a unique and valuable perspective on what it means for an LLM to be "good at code.
1. SWE-bench Verified
SWE-bench (Software Engineering Benchmark) represents a significant shift in evaluation philosophy, moving from isolated, self-contained problems to the complex and messy reality of real-world software development.
Instead of a simple prompt, the model is given access to an entire code repository and a genuine issue description scraped from GitHub. Its task is to act as an AI software engineer: navigate the codebase, understand the problem, and generate a code patch that successfully resolves the issue. The "Verified" subset consists of 500 such tasks that have been manually vetted by human engineers to ensure clarity and correctness.
2. HumanEval & MBPP
HumanEval and MBPP (Mostly Basic Python Problems) are the foundational benchmarks for function-level code generation. HumanEval consists of 164 hand-written Python programming challenges, while MBPP contains around 1,000 crowd-sourced, entry-level problems.
Both are evaluated using the pass@k metric, which measures the probability that at least one of k generated solutions passes a set of unit tests, thereby assessing functional correctness.
3. RepoBench
RepoBench carves out a unique and vital niche in the evaluation landscape by focusing exclusively on repository-level code auto-completion. This task is the bread and butter of developer productivity tools like GitHub Copilot, and RepoBench is the first benchmark designed to systematically measure it in complex, multi-file scenarios. It correctly posits that real-world autocompletion often requires context from beyond the current file.
4. BFCL-v3
BFCL-v3, the Berkeley Function Calling Leaderboard v3, is a highly specialized benchmark designed to measure a model's ability to act as an intelligent agent by using tools.
This task, known as function calling or tool use, is fundamentally different from generating standalone code. It evaluates a model's capacity to interpret a natural language request, identify the correct tool or API from a given set, and then generate the precise, structured call (typically a JSON object) needed to execute it with the correct parameters.
Comparing the Top Coding LLMs: Technical Specifications and Performance
To make informed decisions about coding generation LLMs, it's essential to understand their core technical features, benchmark performances, and licensing terms. Below, we provide clear, concise tables to compare these aspects, along with analyses to contextualize their strategic implications.
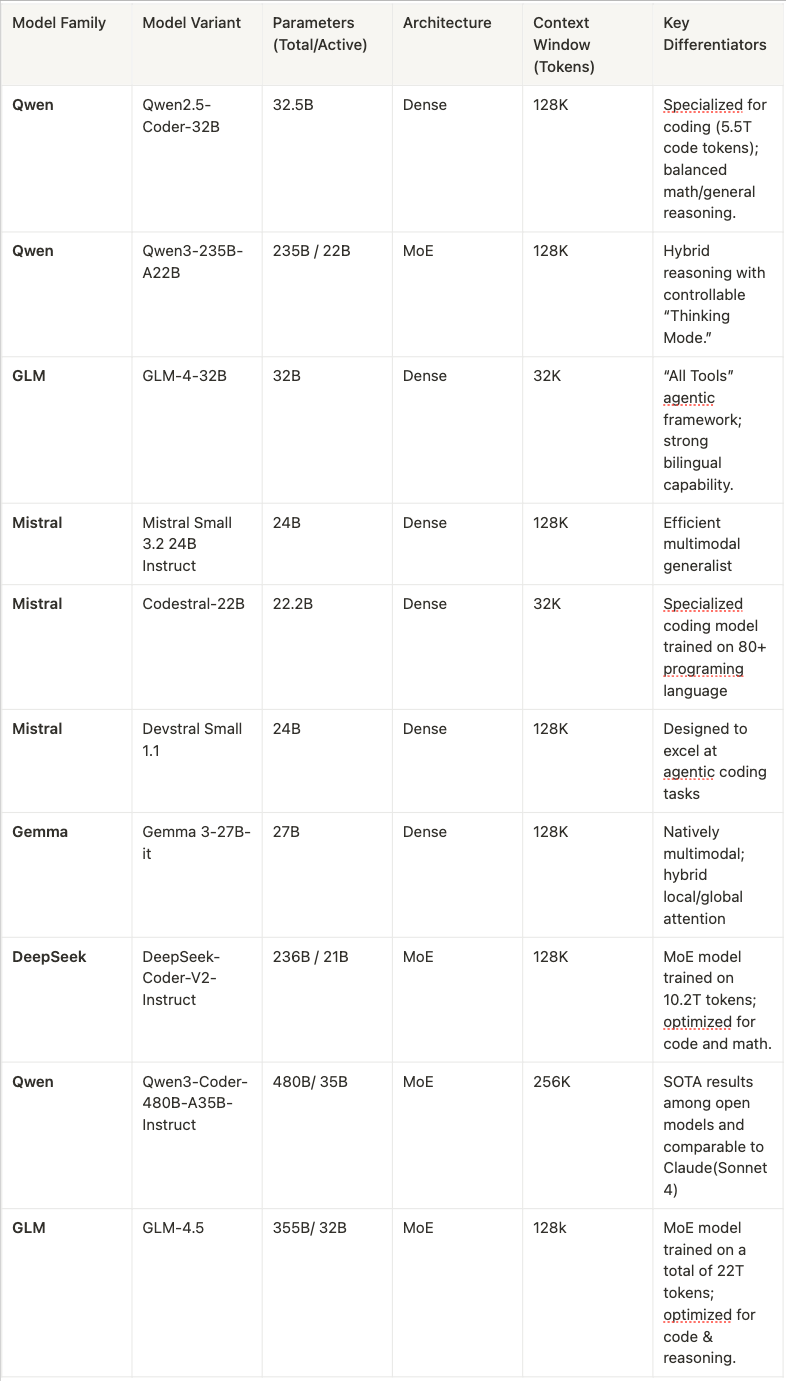
Core Technical Specifications
A quick-reference overview of each model’s key technical attributes, highlighting their design philosophy and intended use-case scenarios:
Multi-Dimensional Performance Comparison
Beyond theoretical specifications, real-world benchmarks provide a concrete measure of model capabilities. Below is a consolidated view of recent coding benchmark results across various models.
/image
The recent releases of GLM-4.5 and Qwen3-Coder-480B-A35B-Instruct have significantly shifted the open models landscape of code generation. These models demonstrate a new level of capability, moving beyond simple function completion to tackle complex, real-world software engineering challenges.
- SWE-Bench: Their performance on SWE-Bench, a benchmark that involves fixing actual bugs and issues in large software repositories. Qwen3-Coder (69.6%) and GLM-4.5 (64.2%), drastically outperforming all other listed models. This signals a major leap towards practical, automated software engineering.
- LiveCodeBench: These models also lead in solving complex algorithmic problems. GLM-4.5 is the top performer with a score of 72.9%, establishing it as a premier tool for advanced problem-solving scenarios.
- Dominance Across Advanced Metrics: On other complex benchmarks like BFCL-v3, where Qwen3-Coder (68.7%) and GLM-4.5 (64.3%) again secure the top spots.
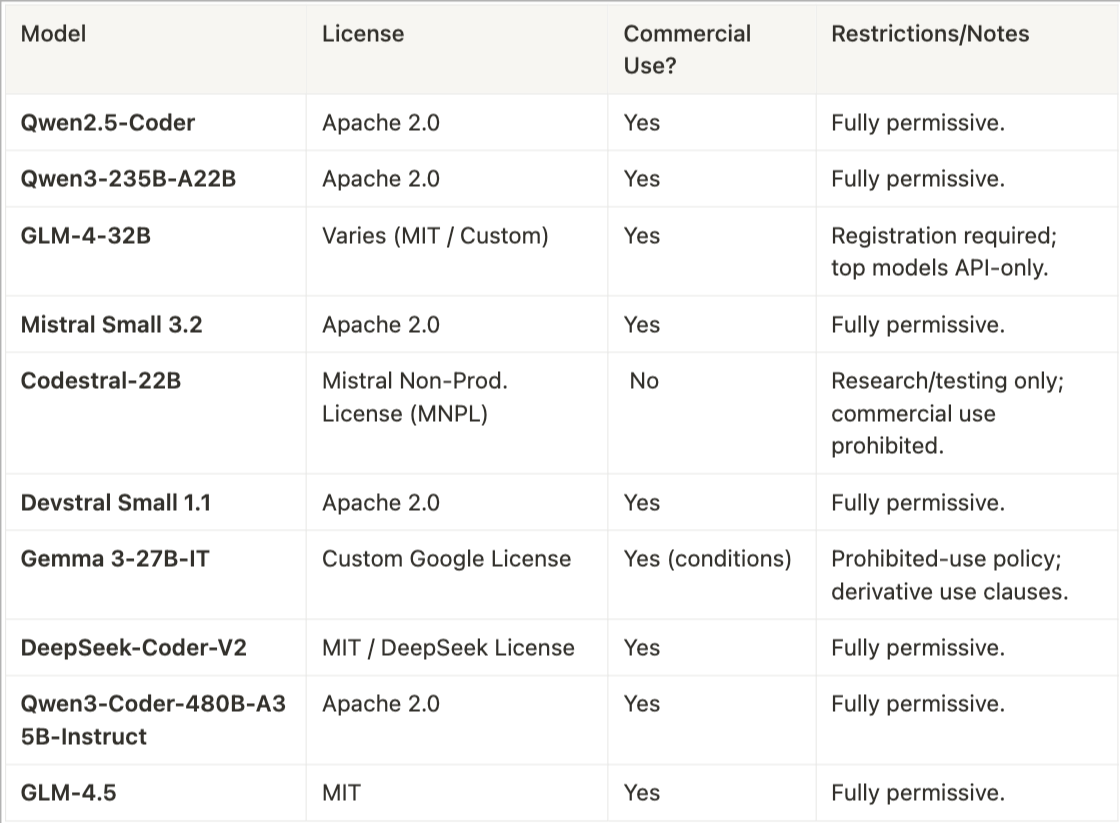
Licensing and Commercial Availability
Licensing status can significantly impact deployment and commercial viability. Here’s a quick-reference licensing summary:
The Emerging Shape of Code Generating LLMs
1. Multimodal & Tool-Aware “Dev Agents”
The top closed-source models can chain tool calls inside their reasoning, letting the model run snippets, search docs or refactor files without leaving chat, parse diagrams or screenshots and output runnable code, broadening “prompt engineering” beyond text.
The latest LLMs don’t just generate text, they produce structured JSON outputs designed to be interpreted and executed as code actions or function calls.
Instead of free-form suggestions, these models emit precise apply_patch, run_tests, or shell_command requests that tooling can parse and execute.
Projects like GLM‑4‑32B‑0414 have been explicitly fine-tuned to support this, using JSON schemas to guide the model toward agentic workflows
2. Smaller, Specialist Models
Enterprises are rapidly adopting small language models(SLMs) to bring coding copilots closer to their source code, hardware and compliance boundaries. Compared with 70B+ giants, today’s SLMs deliver near-parity accuracy on code tasks while cutting inference cost and latency by an order of magnitude, and they can be fine-tuned in less time.
3. Longer Context & “Memory”
Traditional LLMs with 4k–32k windows force painful chunking, breaking code into snippets and hoping the model stitches them together logically. This invariably leads to errors, missing context, and tedious prompt engineering.
Modern code LLMs are changing the game with native 256k+ context windows:
- Qwen3‑Coder‑480B‑A35B‑Instruct ship with a 256k ****token context window 1M tokens with extrapolation methods, enabling you to drop entire multi-file diffs, design docs, and README files directly into the prompt.
Conclusion
The open-source code generation landscape has matured into a complex and multi-faceted ecosystem. The notion of a single "best" model is now obsolete, rendered meaningless without first defining the specific task to be accomplished. The competition is no longer a monolithic race to the top of a single leaderboard but has fragmented into several distinct disciplines, each with its own set of champions and its own relevant evaluation criteria.
The evolution of benchmarks from simple function generation (HumanEval) to real-world software engineering (SWE-Bench) and agentic tasks(BFCL-v3). It is no longer enough for a model to simply write code; it must now demonstrate the ability to understand, debug, and integrate that code within complex, existing systems.
The selection of a model has therefore evolved into a multi-variable equation. A developer must weigh the architectural efficiency of MoE or hybrid attention against the raw power of a dense model. They must align their desired real-world task with the benchmark that best measures it.
Most critically, particularly for commercial ventures, they must navigate a strategic landscape where licensing agreements are used as potent tools to shape the market. The optimal choice requires not just technical acumen but a strategic understanding of this dynamic and rapidly evolving field.