
Deploying Generative AI Models
Experience once more the electrifying AI meetup & After-party, an initiative by Hugging Face, Inferless, and PeakXV Partners. With heartfelt thanks to our speakers, panelists, and participants for their contributions to this triumph! Immerse in the unforgettable insights, dynamic community, and inspiring community demos.
Watch all Videos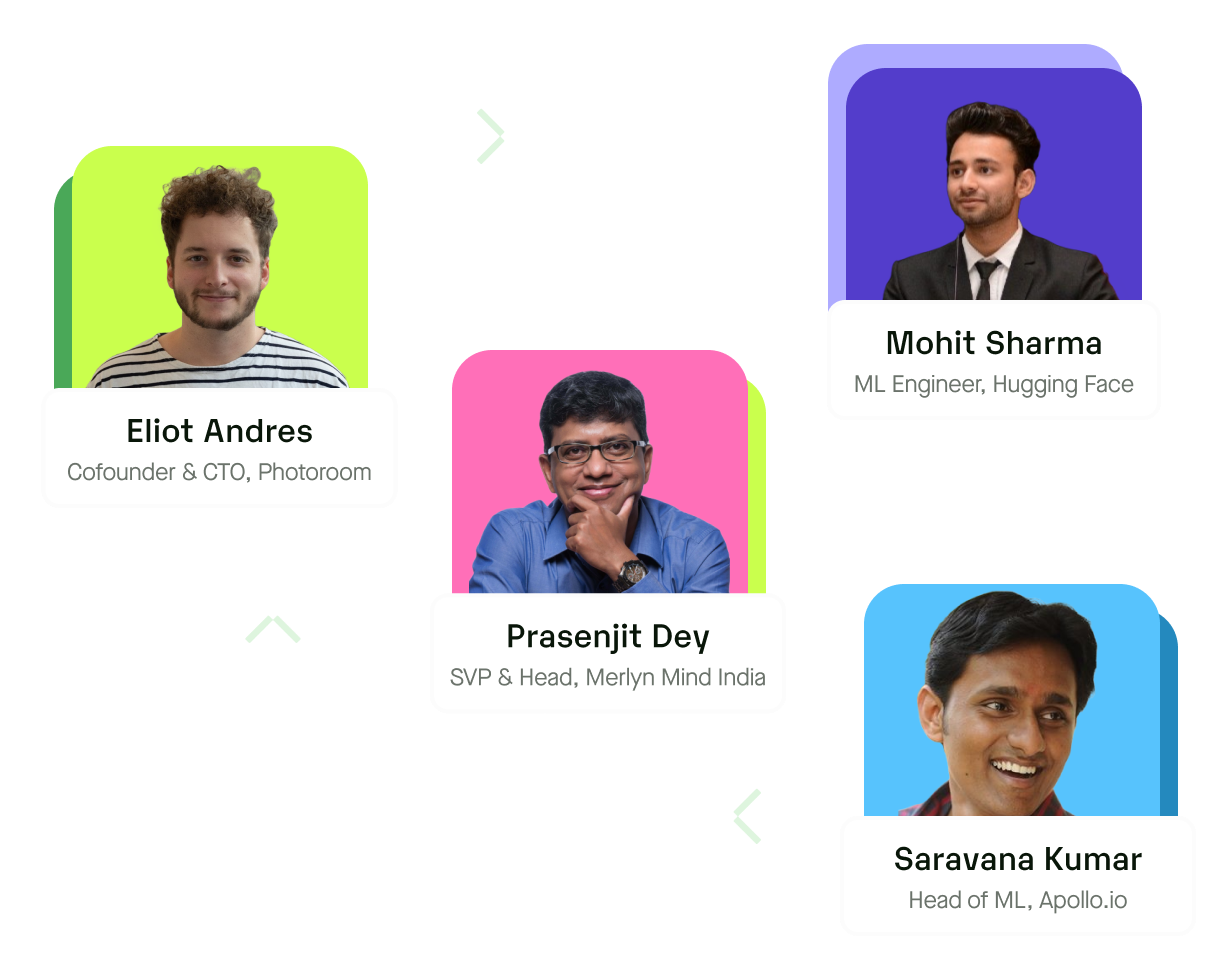
Speakers from

.svg)


Thank you for Joining
Videos

Hugging Face : Optimum
In this session, you'll learn how to harness specialized hardware for optimized model training and deployment, ensuring you stay competitive in the evolving AI ecosystem.

Panel on Deploying Generative AI Models
Discussions around Challenges & Techniques around Deploying Generative AI models by Eliot, Cofounder & CTO of Photoroom, Prasenjit, SVP Innovation at Merlyn Mind, Saravana, Head of Machine Learning, Apollo.io, Moderated by Nilesh, Cofounder & CTO at Inferless

Community Demo : Hexo.AI
Featuring Hexo AI - Helping Brands Maximize Marketing ROI with Generative AI

Community Demo : Ragas
Tool designed for evaluating LLM-generated text and delivering insights about the RAG pipeline.
Community Demo : Neuropixel
Advanced application of AI/ML and statistical learning theory in computer vision and image processing for online retail storefronts.
Glimpse of Excitement: Event Recap Video

.svg)



, @peakxvpartners 💚🤗💚Want to re-live the sessions #IndiaAIDream
Check it out here :